Most teams building a microlearning app reach for the same shape of recommendation system: a single ranker fed features, asked to score every lesson and return the top 50. It works for the first 5,000 lessons. It collapses at 50,000, and it never produces the "this app reads my mind" feeling that defines a TikTok-style feed.
The problem is not the model. It is the architecture. YouTube, TikTok, and Pinterest do not run one ranker. They run four stages, each solving a different problem at a different latency budget. The shape of the system is the moat.
This article is a conceptual deep-dive into that 4-stage architecture for a microlearning app. No code, no SDK calls, just the system design. We will look at why curated and UGC apps need different versions of the same architecture, walk through how Knovo built theirs on FastPix, and end with a 6-step rollout plan.
TL;DR
A modern microlearning recommendation feed runs four stages: candidate generation pulls a few thousand lessons out of the catalog, filtering removes ineligible ones, ranking scores the rest, and re-ranking applies diversity, freshness, and exploration. Curated apps run a lightweight version. UGC apps need the full stack from day one. FastPix sits beside the recommender, not inside it: asset metadata, multimodal embeddings, and Video Data signals flow into the ranker while the video pipeline runs in parallel. TikTok's For-You feed runs a 5.53% engagement rate, more than double Instagram Reels at 2.35% and nearly triple YouTube Shorts at 1.98% (Digital Applied, 2026). The architecture is what unlocks the gap.
The 4-stage recommendation feed architecture
Here is the canonical shape, which YouTube, TikTok, and Pinterest all converge on with minor variations:
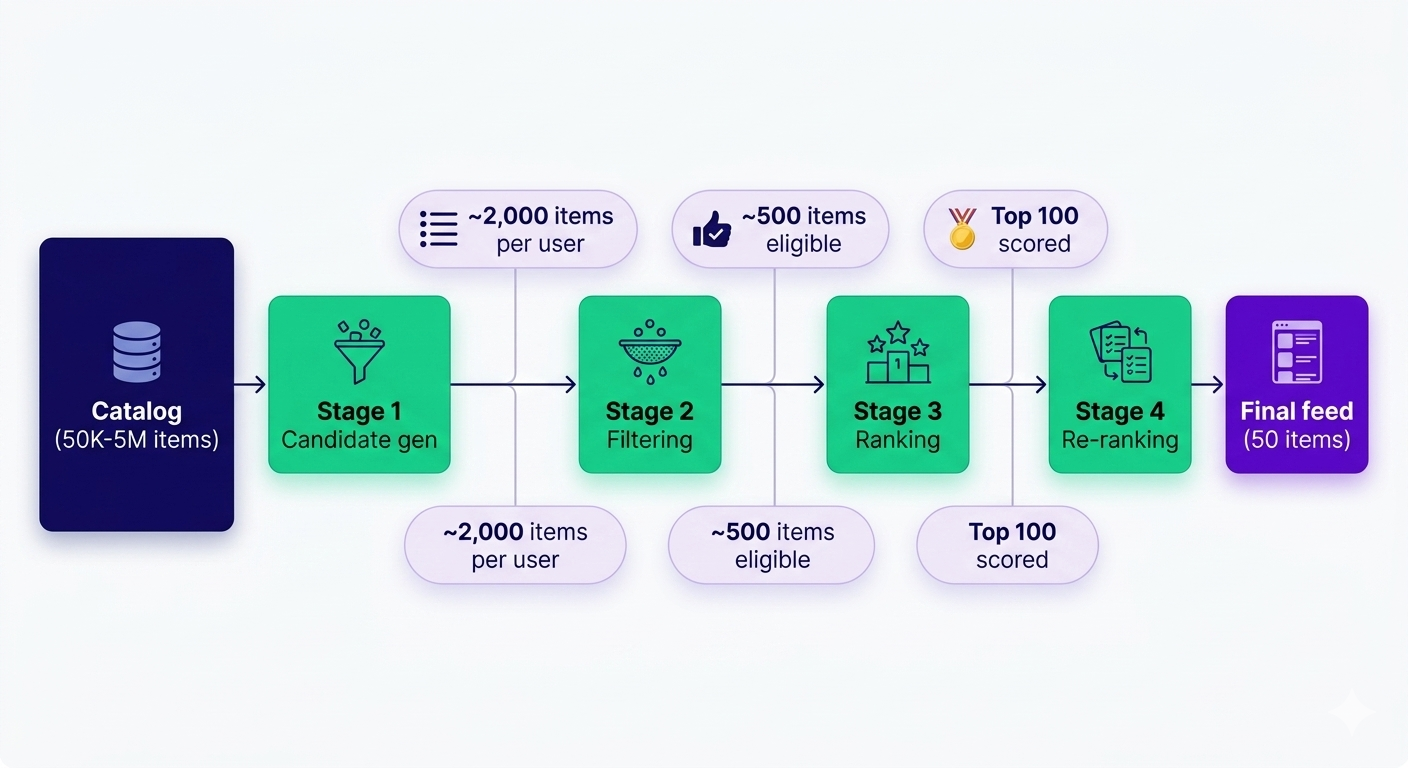
Each stage is a different optimization problem. The wider the catalog, the harder the early stages have to work.
Stage 1: Candidate generation (retrieval)
The first stage takes the entire catalog and returns a few thousand candidate lessons worth scoring. The goal is recall, not precision: throw away 99% without losing anything the user might love.
Three retrieval methods usually run in parallel and merge: collaborative filtering ("users like you also watched"), content-based retrieval (topics the user already engaged with), and embedding-based ANN search. Multimodal embeddings from FastPix In-Video AI plug directly into this stage. The output is cached per user and refreshed every few hours, not on every request.
Stage 2: Filtering (eligibility and business rules)
The second stage removes lessons the user is not allowed to see, or that the product does not want to show. Pure business logic, no ML.
Typical filters for a microlearning app: already-completed, above the user's skill level, wrong language, unpublished, geo-restricted, below quality thresholds. For UGC apps, creator-quality and moderation filters kick in here too. Filtering is the cheapest, most boring stage, and the one that prevents the highest-impact bugs (same lesson twice in a row, region-locked content leaking through). Skip it and the app loses trust in a week.
Stage 3: Ranking (scoring and personalization)
The third stage scores every remaining candidate against the user. This is the stage everyone thinks of when they hear "recommendation system", but it is only one of four.
For a v1 microlearning app, the ranker can be a weighted score: topic affinity × recency × predicted completion probability × predicted quiz pass rate × creator quality (for UGC). No ML, just a tuned formula, and it works surprisingly well for the first 30 to 60 days. Once enough watch and quiz data has accumulated, the ranker becomes a learned model (a two-tower net or a gradient-boosted tree) producing a predicted engagement score per (user, lesson) pair. Features come from user profile, lesson features, and context. Scoring 500 candidates in under 100ms is the typical latency bar.
Mid-article CTA. If you have not picked your video infrastructure yet, the microlearning tech stack guide covers all 9 layers and shows how the FastPix layer collapses 4 of them into one integration. The recommender sits on top of that stack, not inside it.
Stage 4: Re-ranking (diversity, freshness, exploration)
The fourth stage takes the top 100 ranked candidates and rearranges them. This is where the feed stops being a sorted list and starts feeling like a feed.
Three things happen here. Diversification enforces that no more than 2 lessons in a row share topic, creator, or difficulty. Freshness gives new lessons a small score boost so the catalog keeps surfacing fresh content. Exploration injects off-distribution items so the system learns new preferences and prevents monoculture. Without this stage, the feed is mathematically optimal and emotionally dead, and users log off in week 3 because every lesson feels like the last one.
How the architecture changes for curated vs UGC microlearning apps
The four stages are the same. The weight inside each stage is not.
| Stage | Curated microlearning app | UGC microlearning app |
|---|---|---|
| Candidate generation | Metadata-driven (topic graph, skill graph). Catalog small enough that recall is easy. | Embedding-based ANN search across millions of items. Recall is the hardest stage. |
| Filtering | Skill-level, language, already-completed, editorial calendar. | Same, plus creator quality, moderation, copyright, freshness windows. |
| Ranking | Rule-based formula works well. Engagement signals dominate. | Learned model from day 60+. Creator-side and viewer-side signals both required. |
| Re-ranking | Light diversity (mix topics). | Heavy diversity (creators, formats, topics) plus exploration to surface new creators. |
Curated apps can ship a strong feed with a rule-based ranker forever. UGC apps need the full architecture from day one because the catalog is noisy, creator quality varies, and the feed has to defend against rabbit holes. Skipping re-ranking in a UGC app visibly tanks week-2 retention.
Why most microlearning recommendation feeds fail at one shape
The most common mistake teams make is skipping all of the above and shipping a single ranker. That mental model is: fetch all candidates, score them, sort, return top N. It is a sorted list, not a recommendation system, and it produces three failure modes the moment the catalog crosses a few thousand items.
Latency: scoring every lesson per request is O(catalog size) and breaks 100ms p99 budgets. The next video has to render before the swipe finishes. Relevance collapse: without candidate generation, the ranker compares items it has no business comparing. Monoculture: without re-ranking, the feed converges on yesterday's clicks and users churn in week 2.
Each failure mode maps onto a stage that was missing. That is why the architecture is non-negotiable, whether the app is curated or UGC.
How Knovo built it on top of FastPix

Knovo, a published FastPix microlearning customer, runs a curated learning experience and is a clean example of the 4-stage architecture mapped onto a small, editorially-controlled catalog.
The Knovo content team controls what enters the catalog. Every lesson is tagged with topic, skill level, and learning outcome at upload using FastPix asset metadata, which becomes the input:
- Stage 1. Candidate generation walks the topic graph from the user's recent activity outward.
- Stage 2 filters out completed lessons and anything outside the current learning track.
- Stage 3 ranks by predicted completion probability and quiz pass rate, using engagement signals captured by FastPix Video Data.
- Stage 4 is light because the catalog is curated, but still mixes topics so the feed does not feel like one track on repeat.
The interesting part is what Knovo did not build: no encoding pipeline, no ABR ladder, no CDN, no player, no QoE analytics. All of that runs on FastPix and feeds signals into the ranker. The recommendation logic is theirs. The video stack is ours. The two run in parallel and meet at the metadata and event boundary.
How a UGC microlearning app should adapt the architecture
A UGC microlearning app cannot copy Knovo's playbook. The catalog is two orders of magnitude bigger, quality varies wildly, and the system has to actively protect against bad-actor content while still surfacing new creators.
Stage 1: drop metadata-only retrieval as the primary method. Use embedding-based ANN search as the workhorse, with metadata as a secondary signal. Multimodal embeddings from FastPix In-Video AI cover both visual and transcript layers, giving the candidate generator more semantic surface to retrieve against than tags alone.
Stage 2: add a creator-quality filter. Score each creator on a rolling window of completion, report rate, and quiz pass rate. Creators below a quality floor get filtered out or down-weighted. This is the most underweighted stage in most UGC apps and the most valuable to invest in.
Stage 3: the ranker must balance "what the user wants to watch" with "is the content actually a good lesson". Predicted completion alone is not enough. Pair it with predicted quiz pass rate, or predicted 24-hour recall if you have that signal.
Stage 4: push diversification harder. No more than 1 lesson from the same creator in any 5-lesson window. Inject 10-20% exploration. This keeps the feed fresh past month 3.
Mid-article CTA. Building a UGC microlearning app means you also need to track ingest-side analytics. The video analytics for microlearning apps guide breaks down the 7 metrics that decide retention, including the creator-side signals a UGC ranker depends on.
How FastPix supports recommendation feeds without getting in the way
FastPix is intentionally not a recommendation engine. The recommender belongs in your own service, modelled around your users, your content, and your business logic. What FastPix provides is the content layer and the signal layer the recommender depends on.
At the content layer, every asset carries custom metadata at upload time (topic, difficulty, language, skill, creator ID). Multimodal indexing from In-Video AI generates semantic embeddings the candidate-generation stage can ANN-search against. Asset-level metadata is exposed via the FastPix API reference so the ranker can pull lesson features inline.
At the signal layer, every playback event flows out two channels. FastPix Video Data captures startup time, watch duration, completion, and rebuffer events. Webhooks deliver the same events in real time to your event bus, where the ranker consumes them. The recommender updates user features on every play, swipe, and complete event with no beacon code from your engineers.
The two layers run parallel to the playback path. The user's video starts in under a second on the FastPix CDN. The same playback event hits your recommender within milliseconds. Neither one blocks the other.
A 6-step walkthrough to build the feed on top of FastPix
This is the rollout plan, end to end, no code, no SDK calls.
Step 1. Tag the catalogue upload. Every lesson uploaded toFastPix carries topic, skill_level, language, creator_id, learning_outcome in asset metadata. Inputs to Stage 1 and Stage 2.
Step 2. Wire playback events into your event bus. Subscribe to FastPix webhooks and pipe events (started, watched, completed, swiped, completed-with-quiz) into your message bus. Inputs to Stage 3.
Step 3. Ship Stage 1 + 2 with rule-based logic. Candidate generation as a topic-graph walk, filtering as a SQL query on completed lessons. No ML.
Step 4. Ship Stage 3 with aweighted-score ranker. Pick 4 to 6 features (topic affinity, recency, predicted completion, creator quality if UGC) and tune weights manually for the first month. Refreshnightly.
Step 5. Ship Stage 4 with a simple diversifier. Enforce "no two lessons in a row from the same topic or creator", inject 10% exploration. This is what makes the feed feel personalized rather than mechanical.
Step 6. Upgrade Stage 3 to ML once you have data. Train a learned ranker after 30 to 60 days of production engagement data. Start with a gradient-boosted tree; do not jump to deep learning until the tree baseline is well understood.
For the underlying app build, follow the TikTok-style microlearning app guide. FastPix setup itself takes 15 minutes per the get-started-in-5-minutes guide.
Stop hand-rolling the video stack. Build the ranker. Ship the feed.
The differentiated work for a microlearning app in 2026 is the recommender, the curriculum design, and the streak loop. The video stack is plumbing. Spending 4 months building plumbing while a competitor ships a working feed is a strategic mistake, not an engineering one.
Log into dashboard if you have an account. New teams sign up at dashboard ($25 in free credits). For a deeper architectural review, sandbox, or walk-through tailored to your catalog, contact the FastPix team or book a working session. We have helped curated and UGC microlearning teams pick the right shape of all four stages.
Build the four stages. Tag the catalog. Wire the events. Ship the feed.
FAQ
What is the best architecture for a microlearning app's recommendation feed?
The 4-stage recommendation architecture used by platforms like YouTube, TikTok, and Pinterest is the ideal starting point: candidate generation, filtering, ranking, and re-ranking. This structure scales from a few thousand lessons to millions of content items while allowing each stage to evolve independently. Curated microlearning apps can begin with lightweight versions of all four stages, while UGC-based apps typically need the full architecture from day one.
Do I need machine learning to build a recommendation feed for a microlearning app?
Not for v1. The first version of the ranking system can be rule-based using weighted scores across topic affinity, recency, and engagement signals. Machine learning becomes valuable once enough watch data exists to train ranking models, usually after 30 to 60 days of production traffic. Many curated microlearning platforms remain rule-based long-term and still achieve strong retention metrics.
How does FastPix support a recommendation feed?
FastPix operates at both the content layer and the signal layer. Every video asset can include custom metadata, and every playback interaction generates Video Data events or webhooks. Your recommendation engine runs independently in your own service and consumes these signals to drive ranking decisions. FastPix works alongside the recommender without becoming a bottleneck in the ranking pipeline.
How is the recommendation feed different for curated vs UGC microlearning apps?
Curated microlearning apps typically have smaller catalogs and tighter editorial control, allowing candidate generation to rely heavily on metadata while ranking focuses mostly on engagement signals. UGC platforms deal with larger and noisier content catalogs, requiring embedding-based candidate generation, creator-quality scoring during filtering, and stronger diversification strategies to maintain feed quality.
How long does it take to build a recommendation feed for a microlearning app?
A rule-based v1 recommendation system with all four stages can usually be built in 2 to 3 weeks when video infrastructure is already handled by an external platform. An ML-powered ranking system generally becomes a second-phase project that takes an additional 6 to 10 weeks once sufficient watch data is available for model training.



